Even if you know the way, just ask!
Q라는 아이는 알려준다.
어느 방향으로 가는지에 따라 어떤 결과가 생길지에 대해 예측해준다.

너가 이런 상태(state)에서 이런 액션(action)을 하게 되면다면? 이런 결과(quality or reward)를 얻게 될 것이야.
It called " Q-function / state-action value function / Q(state,action)"
Policy using Q-function.
We can choose the method how we can get reward higher and higher.
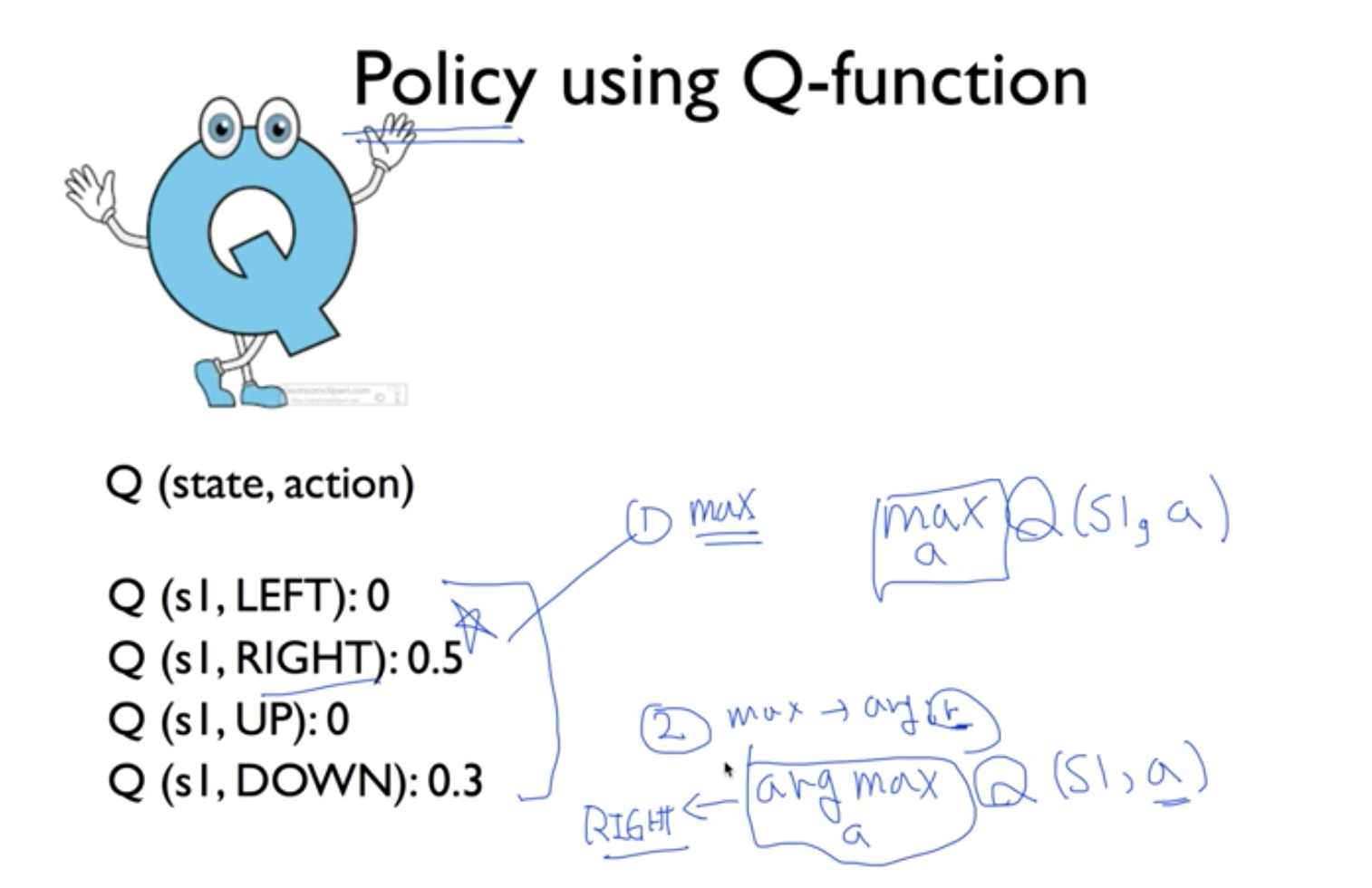

아무튼 우리가 각 방향에 따라 어떤 reward 가 생겼는지 알게되었을 때, 방향을 선택하게 되는데
무엇을 기준으로 하느냐! 어떤 정책으로 갈 것이냐! 이것을 "Policy"라고 부른다.
그 policy는 어떻게 찾는가? 다음과 같은 방식으로 찾게 된다.
1. Q 값중에 가장 큰 값을 어떤거야? 라는 것이고, [ Q가 가진 최대값 ]
2. Q 값을 크게 만드는 값은 어떤거야? 라는 것이다. [ Q가 최대값을 가지도록 해주는 Action의 값 ]
항상 Q가 가질 수 있는 최대값의 방향으로 우리가 움직인다면, 그것은 매우 좋은 방법일 것이다.
[즉 argmax 만을 고려해서 움직이는 방법.]
이를 optimal policy 라고 한다. 기호로는 *를 써준다.
Q는 Q(s,a) 라고 쓰고, s라는 상태에서, 특정 a라는 행동을 했을 때 얻게되는 최대의 reward를 알려주는 함수다.
자 여기서 가장 중요한 것은
이제 그 Q를 어떻게 만들어내느냐는 것이다.
가정을 해야한다.
Assume - s' 에서는 Q가 존재하고 알고 있다고 가정한다.
우리가 알고 싶은 것은 Q(s,a) 이고, Q(s',a')는 알고 있다.
이 상황에서 중요한 것은 reward는 축적이 된다는 것이다.



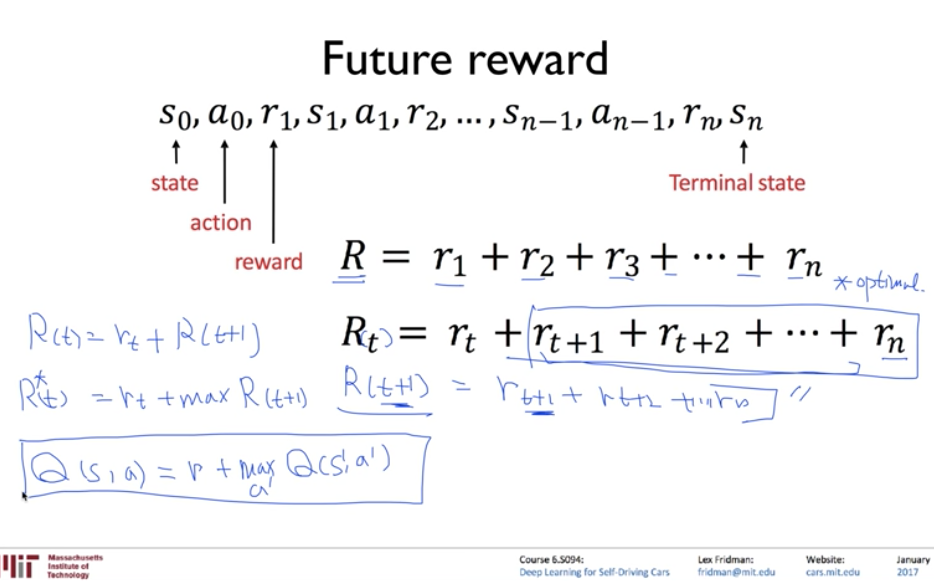
따라서 이를 통해 reward를 표현해보면?
Rt = rt + Rt+1이 된다는 것이 당연하게 된다.
그렇다면 여기서 optimal도 생각해볼 수 있다. ( 다시한번 언급하면 optimal은 max와 몹시 관련이 있는 값이다. )
그리고 오른쪽을 보면 reward와 Q의 관계가 되게 유사하다는 것을 볼 수 있다.


16개의 state와 각 상태별로 action 이 4가지 가 있기 때문에, 16 * 4의 array를 생각해보자.
하지만 우리는 Q에 대해서 모르기 때문에 Initail Q값을 0으로 둔다.
마지막 단에 갔을 때, 계속 0이었던 Q값이 1이 되게 된다. 그것을 기준으로 쭉쭉 연결되서 학습하게 되면


다음과 같이 Q값이 나열될 것이고, optimal policy를 따라서 쭉 이동하게 될 것이다.
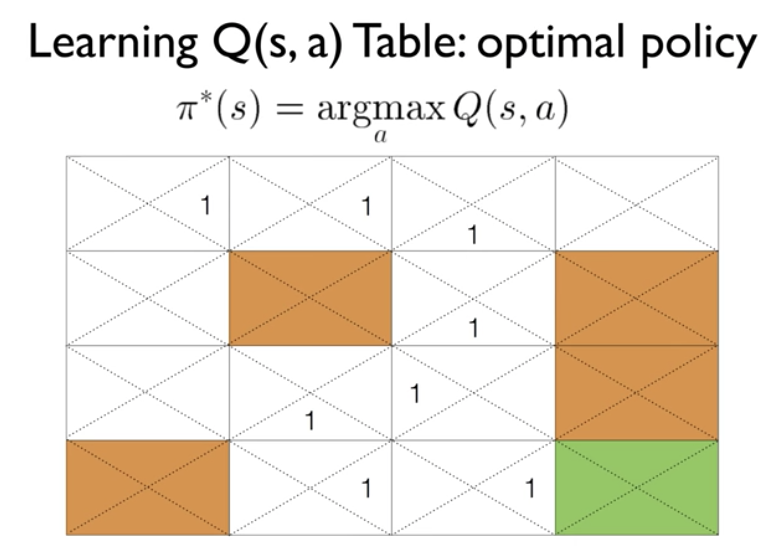
Q테이블을 만들어서 초기화를 시킨다.
환경을 만들어놓고, 상태를 가지고 온다.
그 다음부터는
action 을 하면 1. reward를 받고 2. state가 바뀐다.
그리고 이때마다 우리는 Q를 업데이트 해준다.
어떻게? 지금의 Q는 reward와 다음 상태의 Q로 만들어진다.
이 과정이 반복된다. 계속 업데이트를 하게 된다.




댓글