

저번 시간에 배운 내용을 자세히 보면, Dummy 라는 내용을 볼 수 있다.
이는 어딘가 완벽하지 않은 알고리즘이었기 때문이다.
Dummy Q의 핵심은
[[ 지금의 Q 값은 내가 얻은 reward 와 그 다음 단계에서 얻는 최대 Q의 값으로 정해진다는 것이다. ]]


왼쪽 그림을 보면 우리가 했던 알고리즘을 통해서 보면 다음과 같은 문제를 발견할 수 있다.
optimal policy를 사용해서 왼쪽과 같은 결과를 얻게 되는데, 이것이 과연 옳은 결과일까?
새로운 길을 찾아보려면,
그 값이 1이 아니더라도, 한번 가볼만한 "가치"가 있지 않을까? 라고 생각하게 된다.
이와 같은 생각은 학습할 때 큰 장점을 제공해주기 때문에
기존에 우리가 했던 방식과 함께 나타내어 다음과 같이 "Exploit vs. Exploration 의 문제"라고 말을 한다.
해당 이슈를 우리는 Exploit vs. Exploration 이라고 부른다.
1. Exploit : 내가 가지고 있는 현재의 값을 이용한다.
2. Exploration : 한번 도전을 하겠다. 안 가본 곳에 도전해보겠다! 라는 것을 의미한다.

만약 항상 큰 값만을 따라서 학습을 하게 된다면!
문제가 뭐냐면, 다른 값들에 대해서는 생각해볼 여유가(?) 없게 된다는 것이다.
위와 같은 경우를 살펴보자.
평일에는 찾아보기 귀찮으니까, 내가 아는 맛집을 가서 밥을 먹자.
주말에는 그래도 한번 혹시 보르니까, 새로운 맛집, 메뉴를 찾을 겸 다른 곳에 가서 밥을 먹자.
라는 논리를 세울 수 있다.
Q의 값이 꼭 1을 가질 수 있는 길이 아니더라도, 한번 다른 길을 통해서 도전해볼 수 있지 않을까?
이것이 학습을 진행함에 있어서 더 좋은 방향이 될 수 있다.

이와 같은 방식을 사용해서 Q-learning이 학습을 할 때,
해당 2가지 ( Exploit and Exploration ) 에서 어떤 길을 갈 것인지 선택하게 해주는 것을 E-greedy라고 한다.
위의 예를 보면 어떤 e 값을 줬을 때,
1. 이것보다 작으면 랜덤한 곳으로 ( 10% )
2. 이것보다 크면 내가 알고 있는 길 중에 가장 좋은 길로 간다는 것을 의미한다. ( 90% )

하지만 만약 그 동네에서 10년을 살았으면, 웬만한 맛집을 다 알테니 ( = episode가 클수록 그 환경에 적응할테니까 )
밥먹으러 갈 때, 모든 곳을 계속 랜덤하게 가볼 필요까지는 없다.
따라서 초반에는 random을 크게 하고,
episode 가 증가할수록 그 random의 경우를 작게 ( = 어느정도 규칙적인 선택을 하는 것 )만들어보자. 는 것을 의미한다.
이를 Decaying E-Greedy 라고 한다. ( 앞에는 고정된 확률도 random 하게 가는 것이였는데, 지금은 거듭된 시도가 많아질수록 random 하게 가는 것이 줄어든다는 것을 의미한다. )

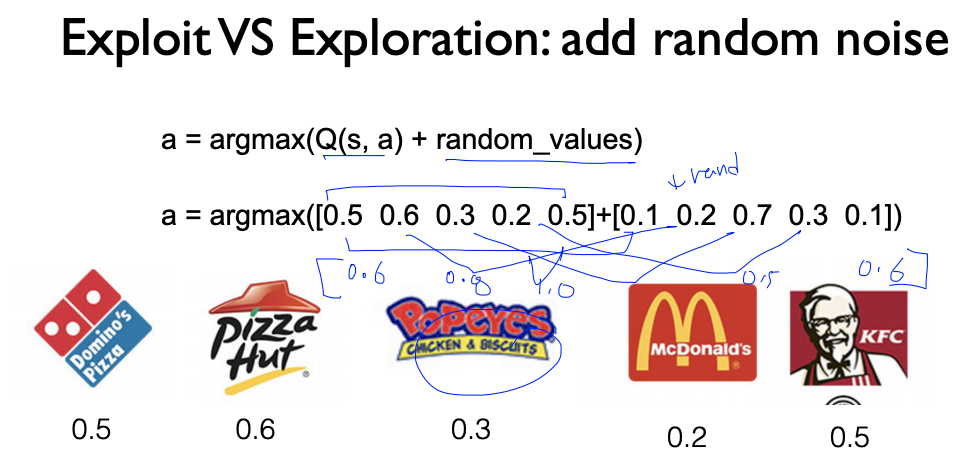

그 다음에 많이 사용하는 방법은 Adding "Random Noise"하는 것이다.
우리가 어떤 것을 선택할지 판단하기 전에
noise 를 추가하는 것이다.
물론 여기에도 Decaying (오른쪽) 하는 방법을 선택해서 할 수 있다.
이는 앞에서 보여준 E-greedy 방법과 다른 형태를 가지고 있다.
가령
E-greedy 방법은 "완전 랜덤하게 도전해보자!."라는 논리를 만들지만,
Noise 방법은 "첫 번째 좋은 식당 말고, 두 번째 좋은 식당으로 가자" 라는 논리가 세워질 수 있다.


따라서 앞으로 우리는 "Select an action a and execute it." 을 사용할 때, Exploit and Exploration 을 쓰게 된다.
이를 사용하게 되면, 기존에 가보지 않았던 길들도 적절히 가보면서 최적의 경로를 만들어낼 것이다.




왼쪽 그림을 보면, Agent가 그려진 곳을 봤을 떄
왼쪽인지 / 아래쪽인지 어디로 가야할 지 헷갈리게 될 것이다.
이것을 해결할 수 있는 방법이 Discounted Reward라는 방법이다.
Learning Q(s,a) with Discounted Reward 라는 방법이다.
이렇게 해주면,
많이 움직일수록 받을 수 있는 상이 적어진다는 것을 알게 된다.

이걸 보면, 위와 같은 위치에 Agent 를 둔다고 하면,
왼쪽으로 가면 보상이 작아진다 ( 0.72 ) 반면 더 빨리 갈 수 있는 아래쪽으로 갈 경우 보상이 커진다. ( 0.9 )
따라서 Discounted reward를 통해 우리가 갈 수 있는 방법이 달라진다.


이제 앞 시간에 배웠던 Dummy Q-learning의 방법을 다 보완해서
위의 그림과 같이 만들어냈다는 것을 확인할 수 있다.

우리가 Q를 이야기할 때,
학습 중간에 우리가 도출해내는 것들은 완벽하고 최종적인 Q가 아니기 때문에
Q^ 이라는 근사치로 써주게 된다.
그렇다면, 이 Q^값을 Q로 수렴하게 되는가? 라는 질문을 할 수 있다.
어떤 방향으로 갔을 때, 항상 같은 상을 받는다.
이 상태의 수가 항상 유한할 때
그때에만 Q^은 Q로 수렴하게 된다.



댓글