Chap. 9 : Regression
Chap. 10 : Dimensionality reduction.
Chap 11 : Density Estimation.
1. Expectation Maximization Algorithm
2. Latent Variable Perspective.
of density estimation with Mixture Models
When? Huge, Representing characteristics ( Gaussian or Beta distribution )


p_{k} : For example - Gaussians, Bernoullis, or Gammas
pi_{k} : Mixture weight.
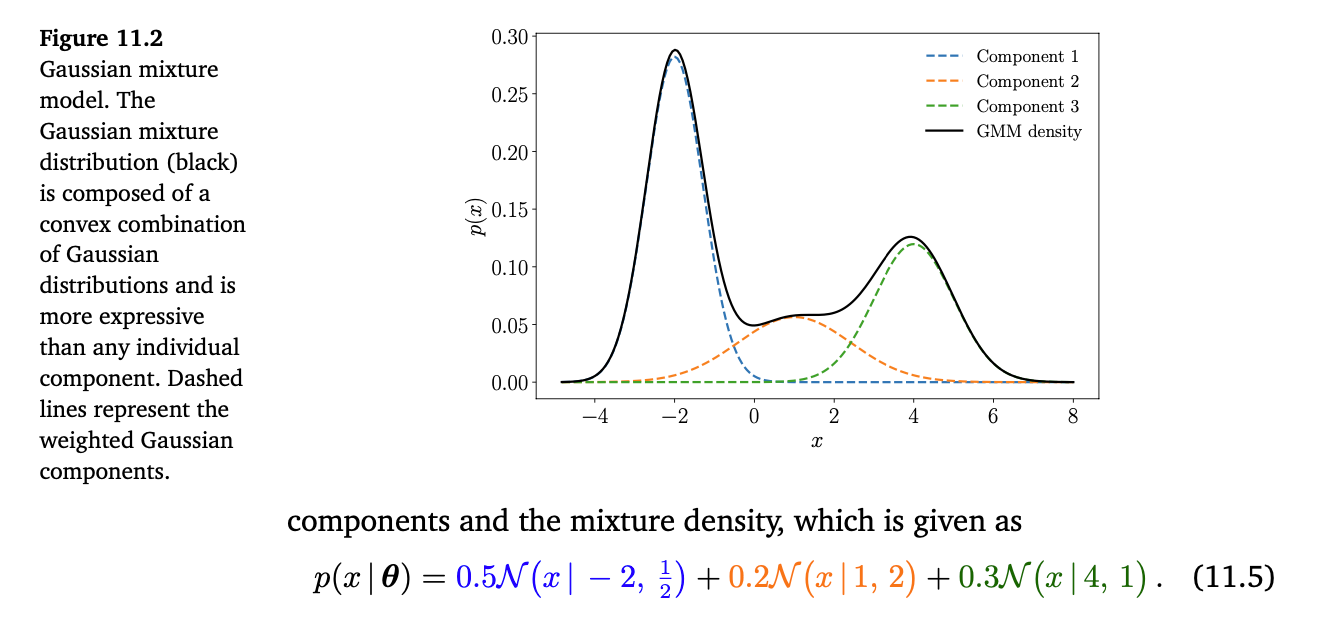
11.1 Gaussian Mixture Model

11.2 Parameter Learning via Maximum Likelihood


In the following, we detail how to obtain a maximum likelihood estimate θ_{M/L of the model parameters θ.
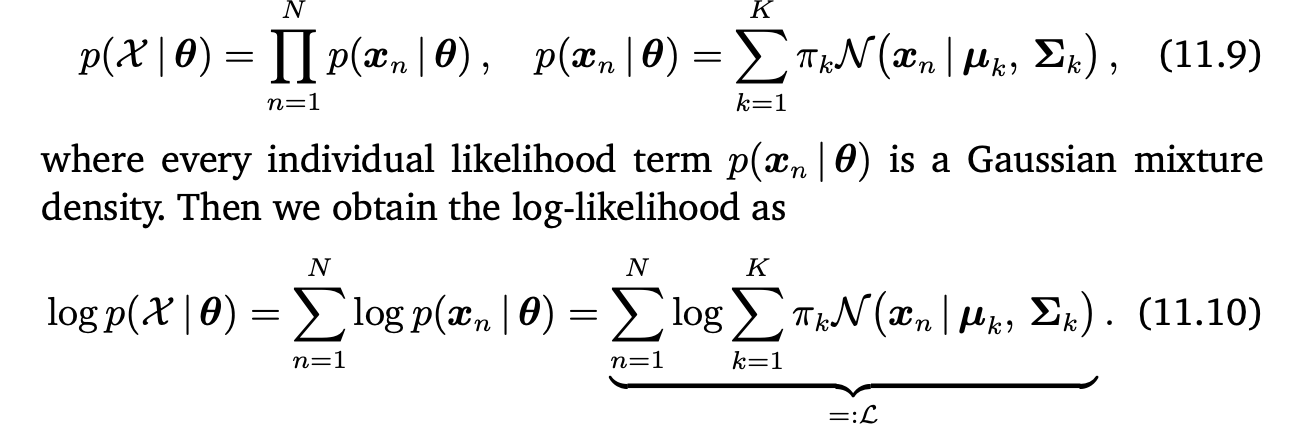
and then -> gradient descent -> set it to "0" -> solve θ ( XX )
we can exploit an iterative scheme to find good model parameter θ_{ML}
Iterative scheme will turn out to be the EM algorithm for GMMs.
The key idea is to update one model parameter at a time [ while keeping the others fixed ]

11.2.1. Responsibilities

mixture components have a high responsibility for a data point when the data point could be a plausible sample from that mixture component
Responsibility = sum -> 1 with r_{nk} >= 0
11.2.2 Updating the Means
update of the mean parameter of mixture component in a GMM. The mean μ is being pulled toward individual data points with the weights given by the corresponding responsibilities.
11.2.3 Updating the Covariances
Effect of updating the variances in a GMM. (a) GMM before updating the variances; (b) GMM after updating the variances while retaining the means and mixture weights.
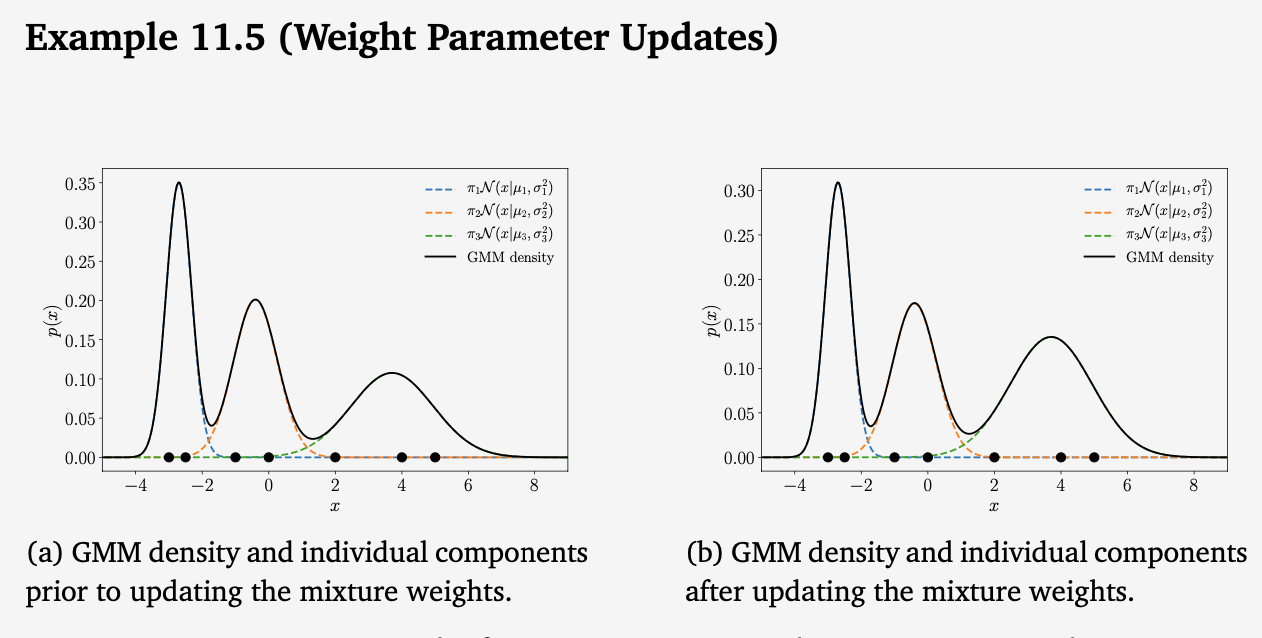
11.2.4 Updating the Mixture Weights
Effect of updating the mixture weights in a GMM. (a) GMM before updating the mixture weights; (b) GMM after updating the mixture weights while retaining the means and variances. Note the different scales of the vertical axes.



'AI > 북 리뷰 - Mathematics for Machine Learning' 카테고리의 다른 글
| 10장 - 1/2 (0) | 2020.01.20 |
|---|

댓글